

イントロダクション

今回は、画像生成AIの『Stable Diffusion』を使用して、『自作LoRA』で自分のキャラを出すために試行錯誤した話をしようと思います。
色々と相談した結果、ブログや動画のサムネで使用するイラストに生成AIを使ってみる事になったんですけど……普通にプロンプトという名の英語の文章を入れるだけだと、自分のキャラを正確に出せない事に気づいたのが発端ですね。

↑一応、こちらが私のアバターのデザインとなりますが……

↑アバターの特徴をプロンプトだけで入力すると、こんな感じで全然似てないキャラしか生成できないので、流石に使えないなーとか思ってたんですけど……
なんか『LoRA』というキャラの特徴を学習させたデータを作れば自分のアバターと同じような画像を簡単に作れるようになるみたいなんで、色々と模索して作成してみた感じです。
全然やった事がない分野なので、ある程度満足する出来になるまで10日くらいかかりましたけどね……。
って事で、ざっくりした備忘録がてら『自作LoRA』作成記録を残しておきますので興味のある人は読んでいって下さいませ。
宜しくお願い致します。
自作LoRAを作ってみた話

では、まずは私の自作LoRAの完成度の変遷から記述していきましょうかね。
※メチャクチャ難航して途中で何度諦めようと思った事か……割と苦行でしたわ。
10日間の試行錯誤の記録

↑まずは一日目の自作LoRAの結果がこれです。
訳が解らない画像でしょう?
これは過学習しまくったせいでLoRAがぶっ壊れたのが原因みたいです。
なんというか、ChatGPTにやり方を聞いて教えられた設定のまんまで学習させたのが最大の敗因ですね。
ちなみに製作時間はRTX3060の12Gモデルで約11時間。学習ステップは脅威の2.3万以上となっております。
今なら1500ステップくらい学習させれば、そこそこ似たようなキャラが出来る事を経験則的に知ってますけど、この頃は何も知りませんでしたから、AIを信用してヤバい代物を作ってしまいました。
11時間もGPUをぶん回して電気代を浪費した結果が、この訳わからんイラストです。
流石に小一時間くらいは凹んだのは記憶しております。

↑二日目の自作LoRAの結果がこれです。
……まあ、最初の意味不明なやつよりは進化したような気がします。
なんか、めっちゃ怖いですけど一応は人間っぽいものが出来たので良しとしましょう。
学習ステップは1000弱くらいで、一個作る製作時間は30分くらいですね。
師匠達に最初の内は失敗しまくるから、経験値が溜まるまでは必要最低限のステップで学習させた方が効率がいいとアドバイスされたので、ここからは数撃ちゃ当たる戦法で粗製乱造しまくる事になります。

↑三日目に作った中では一番マシなやつです。
なんとなく特徴をとらえたものができたような気がしますが、小学生が描いたみたいな稚拙なイラストになってますね。
相変わらず学習ステップは1000弱くらいで、製作時間は30分くらいですが、この日は3つ作ったのでパラメーター調整とか諸々込みで全部で二時間弱くらいはかかってるような気がします。

↑四日目に作った中では一番マシなやつです。
まるで成長していません。
ちょこちょこChatGPTに聞きながら設定変更してるんですけどね。
自信満々に嘘教えるのやめてください、ChatGPTさん。
↑五日目に作った中では一番マシなやつです。
学習ステップを1.5倍に増やして学習モデルも変更したので、ほんの少しだけ進歩したような気もします。前よりは立体感はありますしね。
ちなみにChatGPTに見切りをつけた私は、この日からGeminiにアドバイスを受けながら製作をする事にしました。
さらば、チャッピー。君はこの分野では役に立たなかったよ。
学習ステップは1500弱くらいで、製作時間は1つ作るのに1時間弱くらいになりました。

↑六日目に作った中では一番マシなやつです。
まるで小学生の高学年くらいの子が描いたようなイラストですが、割とオリジナルの特徴を捉えているのでそこそこ完成度が上がってきた感がありますね。
学習ステップは前日と変わりませんが、学習モデルを作る度に変えております。

↑七日目に作った中では一番マシなやつです。
学習用の画像にはキャプションという画像の説明テキストを入れる必要があるんですが、自動ツールではなく自分で一個ずつ書き直したら、かなり完成度が上がりました。
学習ステップは前日と変わりませんが、例によって学習モデルを作る度に変えております。

↑八日目に作った中では一番マシなやつです。
ほぼオリジナルの特徴を捉えたイラストが生成できるようになってきましたが……学習画像が全部私が作ったLive2Dの画像なんで絵柄が完全に固定されて、どうやっても修正できなくなりました。
要するに、どんな画像を出してもこの絵柄になってしまうようになってしまった訳です。
この日から学習ステップを1800に上昇。一個のLoRAを作るのに1.5時間程度かかるようになりました。

↑九日目に作った中では一番マシなやつです。
学習画像が私の自作画像だけだと絵柄が完全固定されてしまうので、半分くらいの画像をGeminiに頼んで3Dにしてもらったりフィギュアっぽいものにしてもらったりしたら絵柄の調整が可能になりました。
……が、絵柄を変更できるようになった代償にオリジナルのデザインとはちょっと隔絶した感じになりましたので、最終日は学習ステップを増やしてみようと思います。
この日の学習ステップは2300。LoRA生成時間は約2時間程度です。

↑最終日の完成版です。
個人的にはキャラの大体の特徴を捉えたものを出せるようになりましたので、もうこれでいいかなって感じです。
最後なんで学習ステップ数は4000にして、より学習深度を高めたものになります。
ちなみにステップ数を5000にしたら過学習になって微妙にデザインがおかしくなったので、私の環境だとここらが学習深度の限界っぽいですね。
サムネに使う程度の素材作成用ですし、なんとなくそれっぽいものが出来たという事でこれで完成でいいでしょう。

↑絵柄も自由に変更できますし、SDモードにもできるんで、そこそこ使い勝手はいいような気はします。ただ、SDモードにするとデザインが微妙に変わるのがネックですが。
多分、完全なSD形態にするには学習画像を全部SDにしないといけないとかなのかも知れません……よく解りませんが。

↑あとは、試しにやってみたら出来た服装チェンジも可能です。キャラLoRAを作ったつもりだったので、標準の巫女服しか作れないのかと思ってましたが、なんか出来ました。

↑ただ、服によっては髪のメッシュ部分とかが正確に表示されなくなったりもするので完全ではないようです。
まあ、予想外の副産物だったのでしょうがないですね。
その内に服装を変える必要が出てきたら、またLoRAを作り直そうかと思います。
って事で、10日間のLoRA作成記録でした。
作成初期にChatGPTに騙されまくって時間を無駄にしましたが、最終的にはそれなりに使えそうなのが出来て私は満足です。
LoRAの作成設定の備忘録
一応、セーブデータがあるのでいつでも同じ設定でLoRAは作れるのですが、普通に忘れる可能性もあるので、必要なものをざっくり書いておきます。
※とりあえず最も必要なのは、そこそこ高性能のグラフィックボード(VRAMが10G以上)だったりしますが、なければないでGoogle ColabあたりでLoRAの作成環境を作るのも可能なので、手間はかかりますが無料で作ろうと思えば作れないこともありません。
まずは一番作るのが面倒な学習用の画像素材ですね。
私が作るのは所謂キャラLoRAなんで、キャラの特徴だけ揃えた画像を30~40枚ほどを必要とします。※当初は20枚くらいから始めて徐々に必要な画像を増やしていった感じですね。
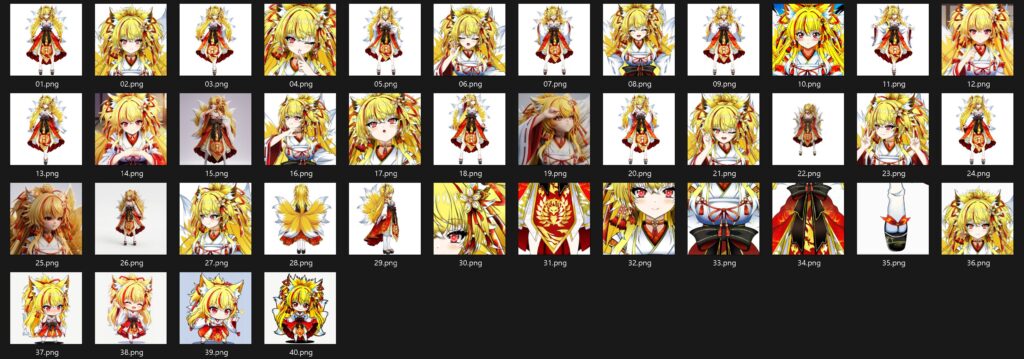
↑今回の最終版に使った学習画像はこんな感じです。
絵柄を揃えるとAIがそれを学習して殆ど画風を変えられなくなってしまうので、Geminiとかであえて違う絵柄とかの画像に変換してもらったものを混ぜております。
髪飾りとかの小物なんかは細部が解るようにアップ画像なんかを混ぜておくといいらしいです。

↑次に二番目に面倒くさいのがキャプションという名のテキストファイル作成ですね。
基本的に画像ファイルに適応するテキストファイルを作成して、その中に英語で画像の説明を書かないといけません。
一応、自動でキャプションを書いて生成してくれるツールもあるんですが、今回のLoRA作成の経験則的には自分で書いた方が完成度が高いものが出来るような感じです。
最初、ChatGPTに聞いたらキャラの名前だけ書いて全部同じ内容でいいとか言われたんで、一個だけキャプションを書いてそのまんま20個全コピペしたら、えらく完成度が低いものが連発で生成されたんで、結構キャプションは大事だと思います。
今回は40枚の画像を使ってるので40個のキャプションを書かないといけませんでしたが、8割くらいはコピペでいけるんで、思ったよりは大変ではありません。ただ単に面倒臭いだけです。
↑例えば、画像01のこいつのキャプションは『shion,kimono, long sleeves, hair ornament, smile, closed mouth,full body,red streaks』だけですし、キャラLoRAを作る場合はキャラ名と最低限の特徴だけ書いておけばいいので簡単です。
ちなみに画風をプラスして書くと、その絵柄を学習してしまうみたいなので今回はあえてキャプションに書かない方向でやっております。
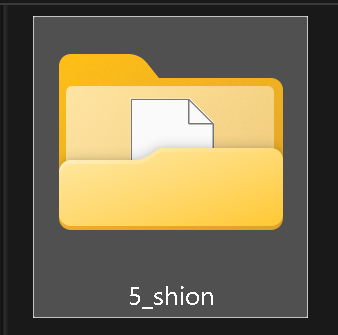
↑完成した学習画像とキャプションは同じフォルダに入れておきますが、フォルダ名の先頭にある数字(上の画像では5)はrepeats回数を示しています。
要するにこの数字が大きいほどに学習回数が増える仕様になっている訳ですね。
最初はChatGPTの指示に従って50くらいの数値を入れてましたが、色々と検証をした結果、画像が40枚くらいあるなら『2~3』くらいの数値で充分にキャラの特徴を持ったLoRAが出来たりします。
なので、あんまり過剰な数値を入れても過学習されて訳わからんイラストになる上に、無駄にGPUをぶん回す事になってGPUの寿命と電気代と貴重な時間が飛ぶという事態に陥りますので、基本的には明らかに学習が足りないなーって感じになった時以外は小さめの数値にした方が無難です。
私はこれで11時間失いました。
先程の画像の5という数値は最終版のものだったので多めの数値になってますけど、試作の中盤以降はずっと2か3でやってましたので、大体の設定が煮詰まるまではそのくらいでいい気がします。
次に必要なのはStableDiffusionを簡単にインストールして管理などができる『StabirityMatrix』と学習ツールである『Kohya_ss』ですね。
まあ、このへんは調べればすぐ出てくるので他の方の説明動画へのリンクとざっくり説明だけしておきます。
↑『StabirityMatrix』のインスール方法はこちらの方の説明を見れば大体わかります。
StabirityMatrixをインストールできたら起動して左の欄から『パッケージ』を選択→画面の一番下にある『パッケージの追加』を選択→上の方にある『Training』タブを選択し、検索窓に『Kohya_ss』と打ち込むと学習ツールである『Kohya_ss』が表示されますのでインストールして下さい。
じゃあ、次に学習モデルの選択ですね。
今回、私はIllustrious系の中でもアニメ系の画像に特化した『animemix_v75』というモデルを使用してますが、汎用的なLoRAを作りたい場合は『Illustrious-XL』とかのスタンダードなモデルを使用した方がいいらしいです。
私の場合は初期に『Illustrious-XL』で学習させてましたが、微妙なものばっかり生成されるので、10個くらいモデルを試した結果、最終的に『animemix_v75』が一番好みっぽい画像が出てきたのでこれを使う事にした次第でございます。
こちらの『animemix_v75』。AIからも癖が強すぎるモデルなので学習には向かないと言われてますので使うかどうかは自己責任でお願いします。
多分、学習させる画像なんかでも学習モデルとの相性関係があるような気がするので、色々と試してみて自分の環境と相性が良さそうなやつを最終的に選べばいいんじゃないかなーとは個人的には思っております。
次にKohya_ssの基本的な使い方ですが、インターフェースは現在のものと若干違いますが↑こちらの動画を見ればなんとなく解るんじゃないかと思います。
重要なパラメーターは、個人的に以下の9個くらいですかね。数値については私が最終的に使ったものとなりますが、使用する学習モデルや学習用の画像にも左右されるっぽいので、参考程度にして下さい。
◎Train batch size:1
◎Epoch:20(Max train epochも同じ数値で)
◎LR Scheduler:cosine
◎Optimizer:AdamW8bit
◎Learning rate:0.0001
◎Text Encoder learning rate:0.00005
◎Network Rank (Dimension):32
◎Network Alpha:16
◎Network dropout:0.1
作ってみてなんか思ったのと違うLoRAになったという方は、Geminiあたりに実際の生成画像をアップして色々と聞いてみるとパラメーターの修正案を提案してくるので試してみて下さい。
経験則的に半分くらい嘘ついてきますが、10回やれば5回くらいは調整成功するので当たりが出る事を祈りましょう。
って事で、超ざっくりLoRA作成設定備忘録でした。
ぶっちゃけ、普通の人なら手間暇かけてLoRA作成するよりも、Geminiあたりに画像を作ってもらった方が手っ取り早いと思いますけどね。

↑最近のGeminiは『なんでもいいので適当にこのキャラで四コマ作って』と指示するだけでこんな感じで割と完成度が高いものを生成してくれますからね。
多分、私みたいに勉強を兼ねてLoRAを作ってみたいという奇特な人間か、成人向けの画像を作りたいという人くらいしか最近はLoRAを作る人は少ないんじゃないかと思います。
個人的に自分でLoRAを作る最大のメリットは自分で色々と調整が出来る事と、ローカル生成できるので無料で枚数制限なしに画像生成できる事くらいな気がしますね。
でもまあ、けっこう作っていて面白かったので、興味がある人はやってみてもいいんじゃないかと思います。
では、本日はここまで。
次項もお時間のある方は読んでいって下さいませ。
↑Live2Dのサブスク購入を御検討の方はこちらからどうぞ。
新規でブログを作りたい方はこちらのレンタルサーバーがお薦めです。⇒≪新登場≫国内最速・高性能レンタルサーバー【ConoHa WING】
動画編集、3Dモデリング用のパソコンをお求めの方はこちらがお薦めです。⇒BTOパソコンのサイコム
今回の経費&記事作成時間&日記

記事作成時間:約4時間
さて。サムネ用のイラスト生成用のLoRAも出来たので、ぼちぼち動画のテンプレの方を作成開始しました。
動画でLive2Dを使うのは思った以上に手間がかかりそうなんで、幾つか自動化できないかAIと相談中です。
だって、今のまんまだとPSDツールキットの約2.5倍くらい時間かかりますし。
あんまりLive2Dで手動の動画を作ってる人がいないのは、この製作コストが原因じゃないかと思いますわ。
なるべく簡単に作れるように簡略化できる所は簡略化して、テンプレ化できるとこはやっていく事にしましょう。
って事で、AIに丸投げしてPythonでなんかプログラムを組んでもらって色々と楽にやれたらいいなって感じで裏で何やかんや画策している今日この頃です。
まあ、ちゃんと形になるのかどうかは解りませんけどね。
では、最後に恒例の累計出費&記事作成時間を発表して終わりにしましょう。
総制作時間:約2646時間
累計支出:272,274円